Introducción
La regresión logística es uno de los modelos lineales generalizados más utilizados debido a su amplia gama de aplicaciones. Puede ser utilizado para conocer la probabilidad de que ocurra un suceso dado un conjunto de covariables, e incluso es utilizado como algoritmo de Machine Learning para realizar clasificaciones binarias (diagnóstico clínico, spam en correos electrónicos y reconocimiento de imágenes, entre otras).
Sin embargo, en la experiencia práctica, existen casos donde los algoritmos para realizar estimaciones de máxima verosimilitud no convergen y muchos investigadores no tienen claras las causas del problema ni cómo solucionarlo (Allison, 2008).
Según Albert & Anderson (1984), este problema tiene dos causas principales: la separación completa y la separación cuasicompleta, las cuales causan que, al no converger los algoritmos de estimación por máxima verosimilitud, algunas de las estimaciones o todas sean infinitas. Con separación completa, las salidas para cada sujeto en el conjunto de datos pueden ser perfectamente predichas, mientras que con separación cuasicompleta esto sucede para un subconjunto de sujetos.
Muchos han sido los esfuerzos por resolver este problema. En particular, el trabajo de Heinze & Schemper (2002) es uno de los más referenciados y consiste en realizar una modificación a la función score de la regresión logística utilizando un método que fue originalmente desarrollado por Firth (1992) para reducir el sesgo en las estimaciones de máxima verosimilitud.
Regresión Logística
Para los modelos lineales generalizados, partimos del predictor lineal:
El cual se relaciona con mediante , esta función es llamada función de enlace y está relacionada con la distribución de la variable de respuesta y su representación en la familia exponencial de dispersión. De la cual se deduce que:
Y finalmente se obtiene:
Estimación por Máxima Verosimilitud
Tengamos en cuenta el problema de regresión logística para datos no agrupados donde la variable de respuesta representa la ocurrencia de un evento de interés:
Esto implica que , recordemos que . Si llamamos a la función de masa de probabilidad (fmp) de tenemos:
Para una muestra aleatoria , la función de verosimilitud está definida por:
Si es la log verosimilitud, se tiene:
Finalmente, si reemplazamos los resultados de (1) en la ecuación anterior, se obtiene:
La Función Score
Para encontrar los estimadores de máxima verosimilitud, necesitamos derivar la log verosimilitud con respecto a e igualarla a cero. La derivada parcial de con respecto a es:
Recordando que , podemos reescribir la derivada como:
El vector de derivadas parciales, conocido como función score, es:
donde es el vector de covariables para la observación -ésima.
Los estimadores de máxima verosimilitud se obtienen resolviendo el sistema de ecuaciones:
Este sistema de ecuaciones no tiene solución analítica cerrada, por lo que se requiere el uso de métodos iterativos como Newton-Raphson o Fisher Scoring para encontrar los estimadores.
Matriz de Información de Fisher
La matriz de información de Fisher juega un papel crucial en la estimación y en las soluciones al problema de separación. Esta matriz se define como el valor esperado del negativo de la matriz Hessiana (segundas derivadas) de la log verosimilitud:
Para la regresión logística, la matriz de información de Fisher tiene la forma:
donde es la matriz de diseño con filas y es una matriz diagonal con elementos .
La matriz de información de Fisher es importante porque:
-
Inversa de la matriz de covarianza asintótica: La matriz de covarianza asintótica de los estimadores de máxima verosimilitud es .
-
Errores estándar: Los errores estándar de los coeficientes se obtienen de los elementos diagonales de .
-
Penalización de Firth: La penalización de Firth utiliza esta matriz para modificar la función score y prevenir la separación.
El Problema de Separación
Separación Completa
La separación completa ocurre cuando existe un vector tal que:
En este caso, todos los valores de la variable de respuesta pueden ser perfectamente predichos por el modelo.
Separación Cuasicompleta
La separación cuasicompleta ocurre cuando existe un vector tal que:
Con al menos una igualdad estricta. En este caso, un subconjunto de observaciones puede ser perfectamente predicho.
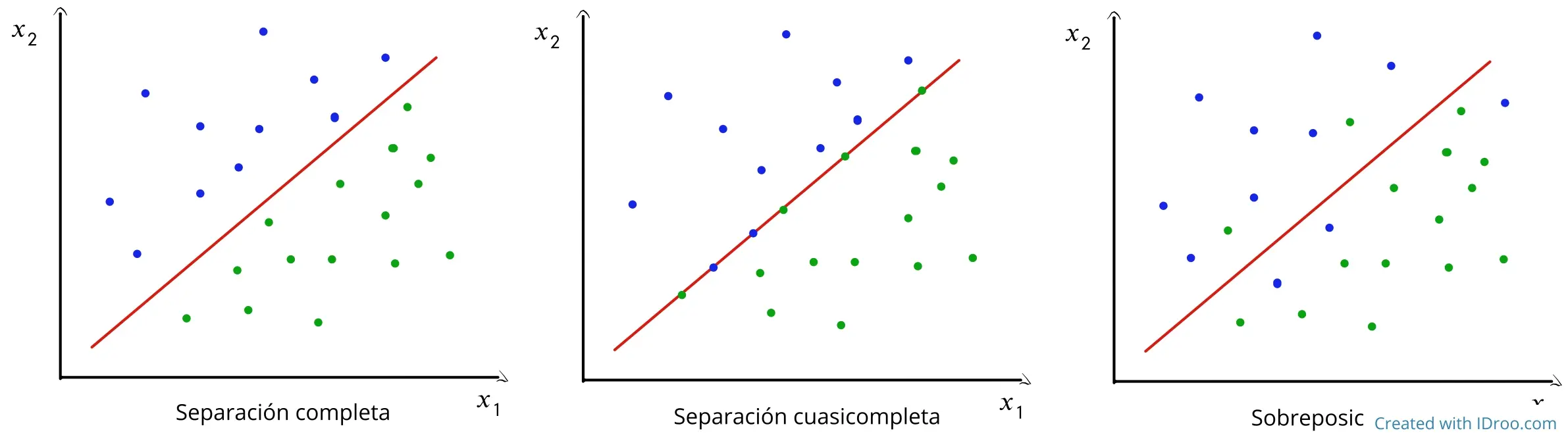
Figura 1: Ejemplo de separación completa en un conjunto de datos. Los puntos de diferentes clases están perfectamente separados por una línea de decisión.
Consecuencias
Cuando ocurre separación (completa o cuasicompleta):
-
Los algoritmos de optimización no convergen: Los métodos iterativos como Newton-Raphson o Fisher Scoring no logran encontrar una solución finita.
-
Estimaciones infinitas: Algunos o todos los coeficientes tienden a infinito.
-
Errores estándar muy grandes: Los errores estándar de los coeficientes se vuelven extremadamente grandes, haciendo que las pruebas de hipótesis sean poco confiables.
-
Probabilidades predichas extremas: Las probabilidades predichas tienden a ser 0 o 1, lo que puede ser problemático para interpretación.
Soluciones al Problema de Separación
Penalización de Firth
La penalización de Firth (Firth, 1992) modifica la función score agregando un término de penalización basado en la información de Fisher:
donde es la matriz de información de Fisher. Esta modificación reduce el sesgo de las estimaciones y previene la separación.
Regularización
Otras alternativas incluyen:
-
Ridge Regression (L2): Agrega un término de penalización a la función de verosimilitud.
-
Lasso (L1): Agrega un término de penalización a la función de verosimilitud.
Ejemplo Práctico
Consideremos un caso de clasificación de clientes morosos de un banco. Supongamos que tenemos datos con dos covariables y , y una variable de respuesta binaria que indica si el cliente es moroso (1) o no (0).
Datos con Separación Completa
Cuando intentamos ajustar un modelo de regresión logística estándar, obtenemos:
Warning messages:
1: glm.fit: algorithm did not converge
2: glm.fit: fitted probabilities numerically 0 or 1 occurred
Esto indica que hay separación en el conjunto de datos. Los coeficientes estimados pueden ser extremadamente grandes y los errores estándar muy grandes, como se muestra en la siguiente tabla:
Tabla 1: Resultados de la estimación por máxima verosimilitud con separación
Estimate Std. Error z value Pr(>|z|)
(Intercept) 639.6329 176750.0035 0.00 0.9971
x1 -25.4392 6923.6497 -0.00 0.9971
x2 -25.4442 17615.1711 -0.00 0.9988
Como se puede observar, los coeficientes son extremadamente grandes y los errores estándar son desproporcionadamente grandes, lo que hace que los valores z sean prácticamente cero y los p-valores sean cercanos a 1, indicando que el modelo no puede proporcionar inferencias confiables.
Nota: La Figura 1 mostrada anteriormente ilustra visualmente cómo se ve la separación completa en los datos, donde las clases están perfectamente separadas.
Solución con Penalización de Firth
Para solucionar este problema, utilizamos la penalización de Firth en la función score, la cual se realiza en R con el paquete logistf:
library(logistf)
# Ajustar modelo con penalización de Firth
lr2 <- logistf(y ~ x1 + x2, data = data)
summary(lr2)Los resultados muestran que:
- No hay mensajes de error: El algoritmo converge correctamente.
- Estimaciones finitas: Todos los coeficientes tienen valores finitos y razonables.
- Predicciones perfectas mantenidas: El modelo mantiene la capacidad de hacer predicciones perfectas, pero con estimaciones estables.
Un ejemplo de salida del modelo con penalización de Firth sería:
Model fitted by Penalized ML
Coefficients:
(Intercept) -32.567000 14.3902050 -136.3499317 -11.597743 33.652444
x1 1.265011 0.5566551 0.4609679 5.171369 60.204715
x2 1.858898 1.6290107 -3.1716557 10.285348 1.084355
likelihood ratio test = 62.76578 on 2 df, p = 2.342571e-14
Como se puede observar, ahora los coeficientes son finitos y razonables, y el algoritmo converge correctamente sin mensajes de advertencia.
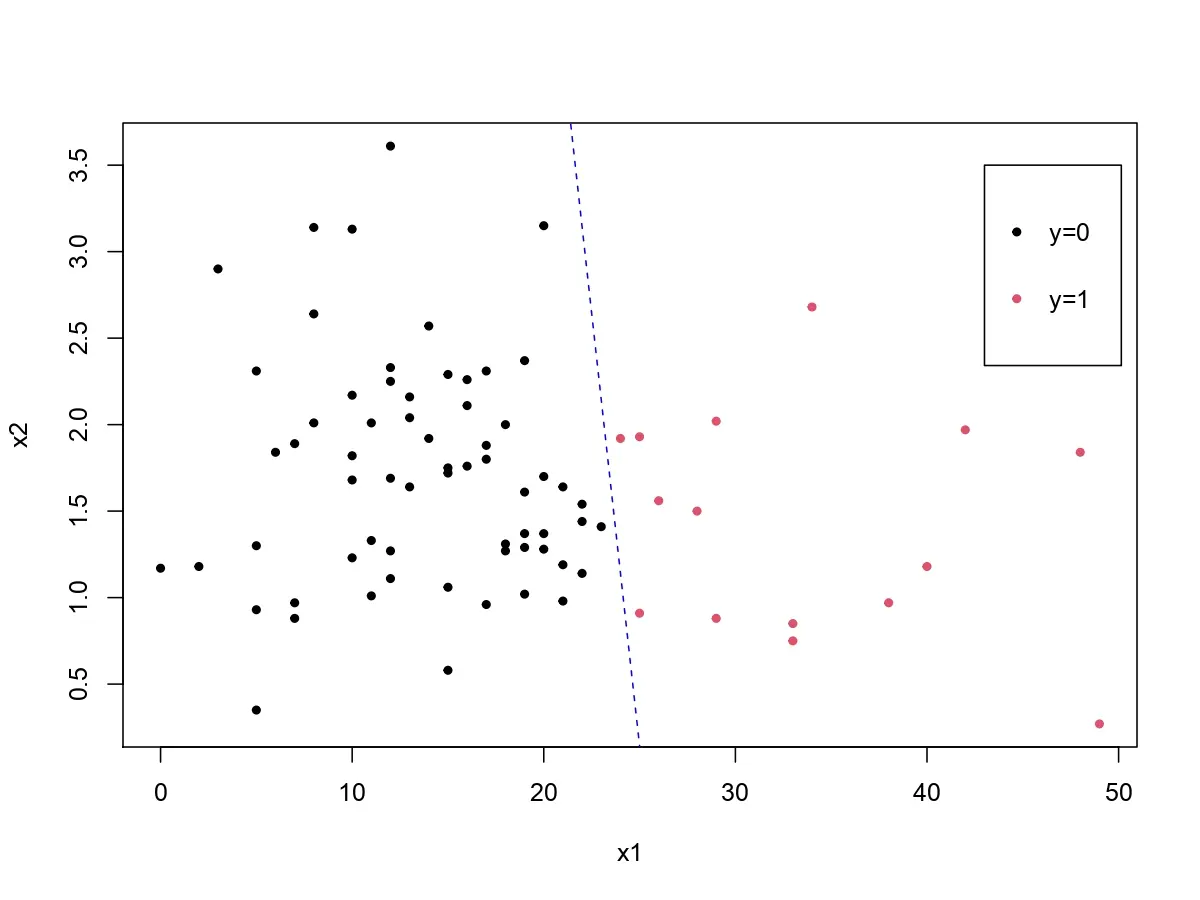
Figura 2: Gráfica de dispersión de los datos y banda de decisión estimada con Máxima verosimilitud penalizada. El modelo penalizado también genera estimaciones perfectas ante la separación completa, pero en este caso, sí convergen los estimadores, lo que hace que sea más creíble el modelo. Se observa que la línea de decisión (en azul) separa correctamente las clases mientras mantiene estimaciones finitas y estables.
Diagnóstico de Separación
Para diagnosticar si hay separación en los datos, podemos:
-
Revisar los mensajes de advertencia: Si aparecen mensajes como “algorithm did not converge” o “fitted probabilities numerically 0 or 1”, hay indicios de separación.
-
Revisar los coeficientes: Si los coeficientes son extremadamente grandes (por ejemplo, > 10 o < -10), puede haber separación.
-
Revisar los errores estándar: Si los errores estándar son muy grandes en relación con los coeficientes, es un signo de separación.
-
Visualizar los datos: Un gráfico de dispersión puede revelar si las clases son perfectamente separables. El código R proporcionado incluye funciones para generar estos gráficos y visualizar la línea de decisión.
Conclusiones
La separación es un problema poco frecuente pero hay que tener cuidado con él, ya que se puede tener mucho sesgo en las estimaciones al estar frente a algoritmos que no convergen. Aunque muchos autores hablan de la separación como un problema, hay otros que hablan de ella como un buen resultado, pues lo que se espera son predicciones perfectas. Sin embargo, con los resultados de este trabajo se puede observar que la solución por penalización corrige el problema de convergencia de los algoritmos sin sacrificar las predicciones perfectas.
Con base en lo anterior, se recomienda que cuando se tengan problemas de separación y convergencia en los algoritmos, se utilicen métodos de penalización como el de Firth o la regularización, con el ánimo de corregir estos problemas, pues al momento de presentar tu modelo será más confiable un modelo con estimaciones que convergen, manteniendo las buenas predicciones del mismo.
Referencias
-
Albert, A. & Anderson, J. A. (1984). On the existence of maximum likelihood estimates in logistic regression models. Biometrika, 71(1), 1-10.
-
Allison, P. D. (2008). Convergence failures in logistic regression. SAS Global Forum, 360, 1-11.
-
Correa, J. C. & Valencia, M. (2011). La separación en regresión logística, una solución y aplicación. Revista Facultad Nacional de Salud Pública, 29(3), 281-288.
-
Firth, D. (1992). Bias reduction, the jeffreys prior and glim. In Advances in GLIM and Statistical Modelling (pp. 91-100). Springer.
-
Heinze, G. & Schemper, M. (2002). A solution to the problem of separation in logistic regression. Statistics in Medicine, 21(16), 2409-2419.
-
Mansournia, M. A., Geroldinger, A., Greenland, S. & Heinze, G. (2018). Separation in logistic regression: causes, consequences, and control. American Journal of Epidemiology, 187(4), 864-870.
-
Rindskopf, D. (2002). Infinite parameter estimates in logistic regression: Opportunities, not problems. Journal of Educational and Behavioral Statistics, 27(2), 147-161.